Designing the layer between your data and your vendors.
Datadog Observability Pipelines · 2022–2023

Datadog acquired Vector, an open-source telemetry pipeline tool, and the bet was to build a control plane around it for enterprise customers. Most teams were ingesting trillions of log events a month, paying vendors to store noise, and locked into whichever platform their data already lived in. If we could give customers a layer to manage their telemetry before it hit any vendor – including us – we'd become the layer they trust for cost, compliance, and routing.
I was the only designer on it from pre-launch through GA, working with a PM, our VP of Product, around 8 engineers, and the OSS Vector team. I owned every surface: the visual builder, the deploy flow, the health views, and the worker management UI.
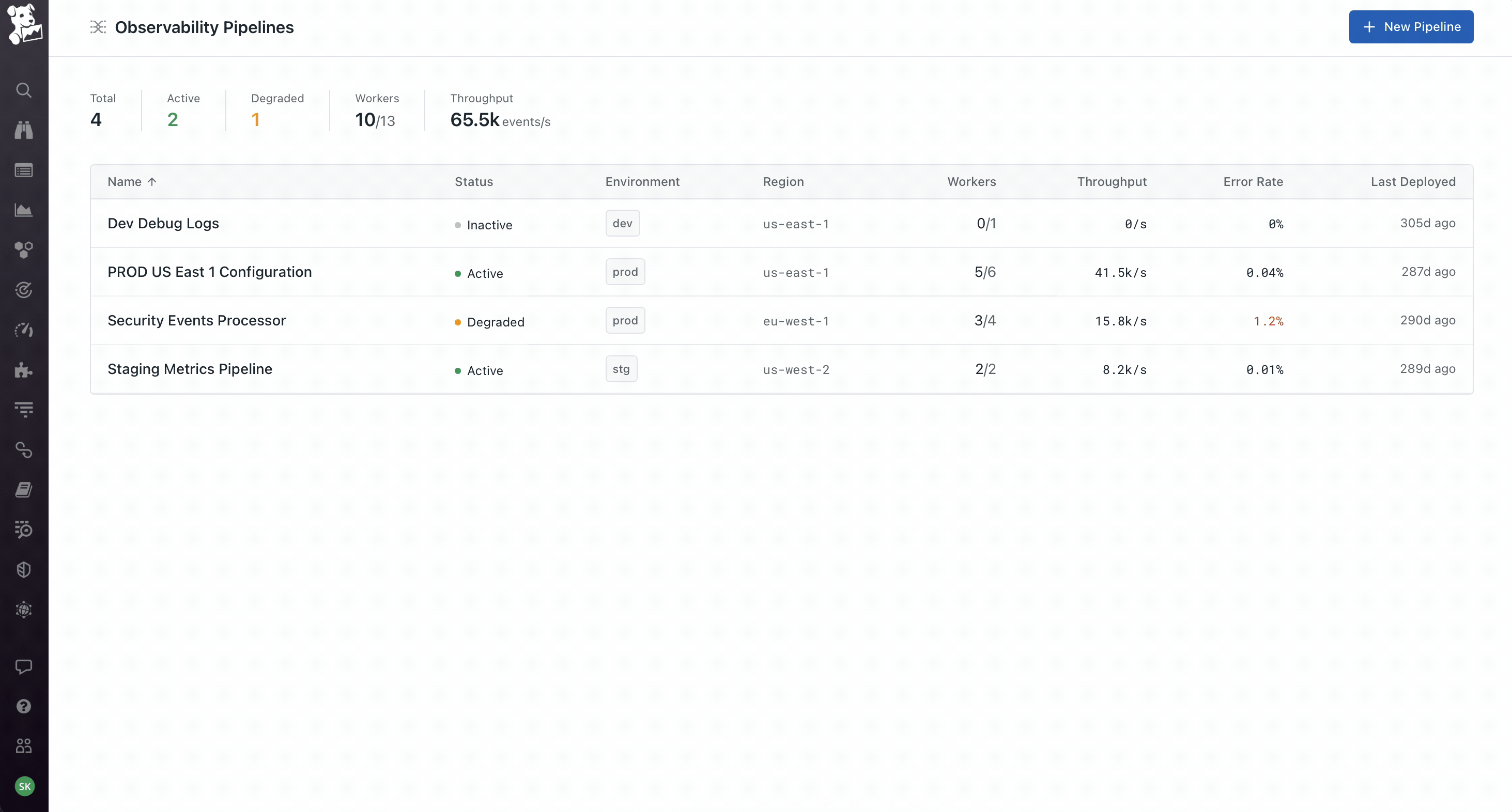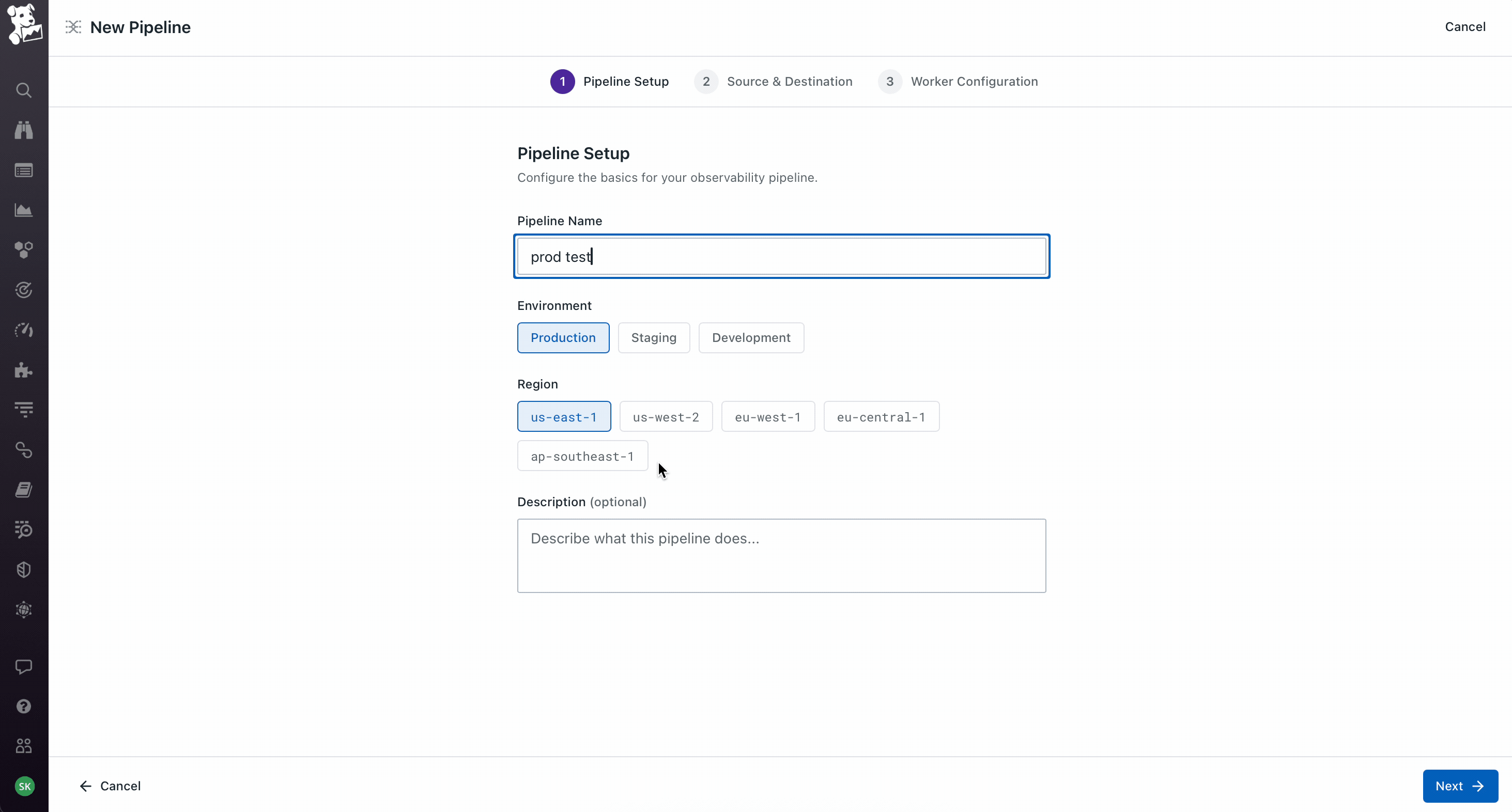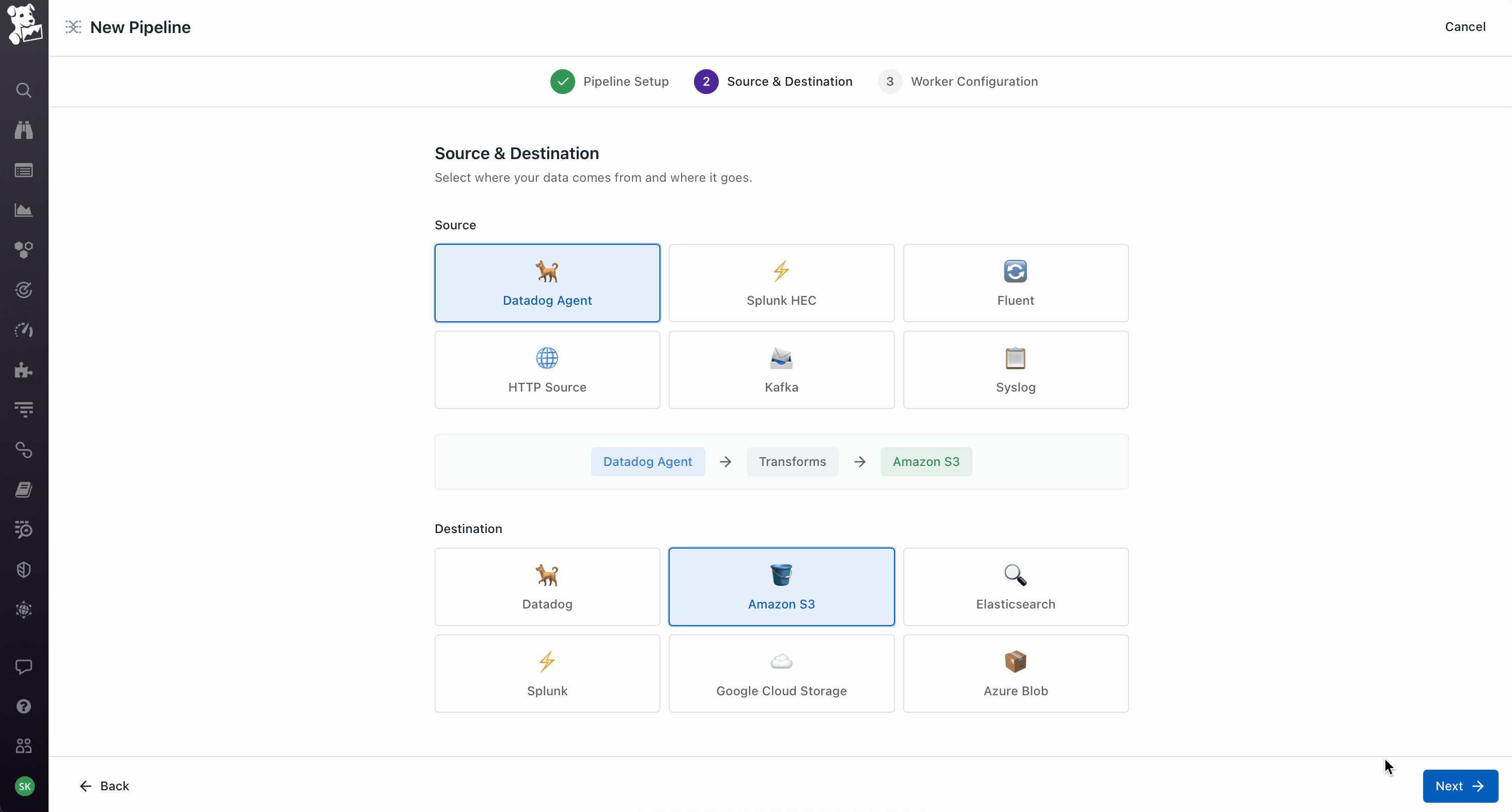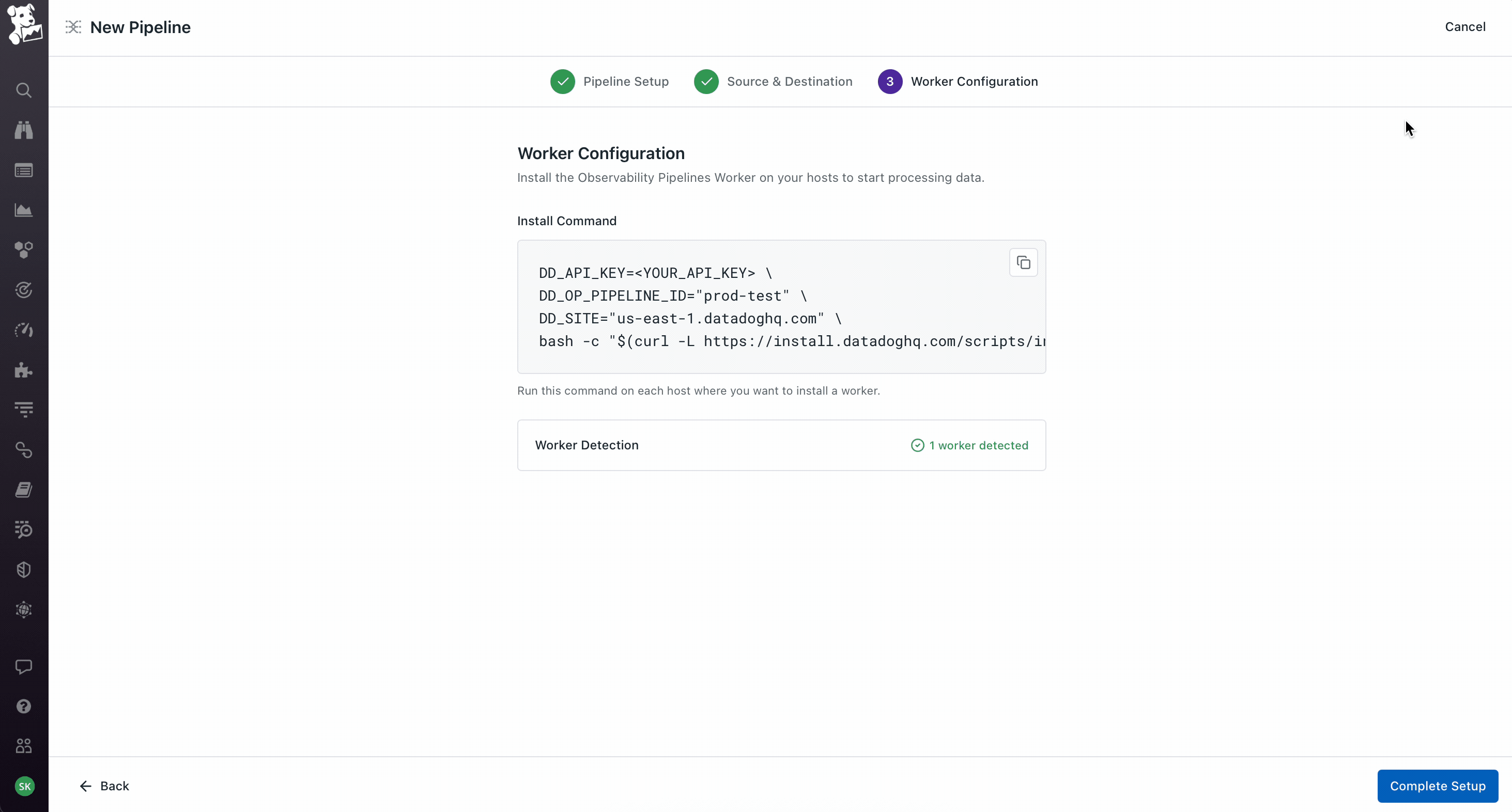
The product itself is straightforward to describe – collect telemetry from any source, transform it however you want, route it to any destination. 42 sources, 14 transforms, 51 destinations at the time we shipped. The hard part was that the pipeline is authored visually in Datadog's cloud, but it actually runs as code on a worker the customer deploys in their own infrastructure. So you have visual authoring on one side and code-based execution on the other, and the data moving through it is production telemetry, which means if anything about the handoff feels off, customers lose visibility into their entire stack. Most of the design work was about making that handoff feel safe.
A few of the decisions that shaped the product:
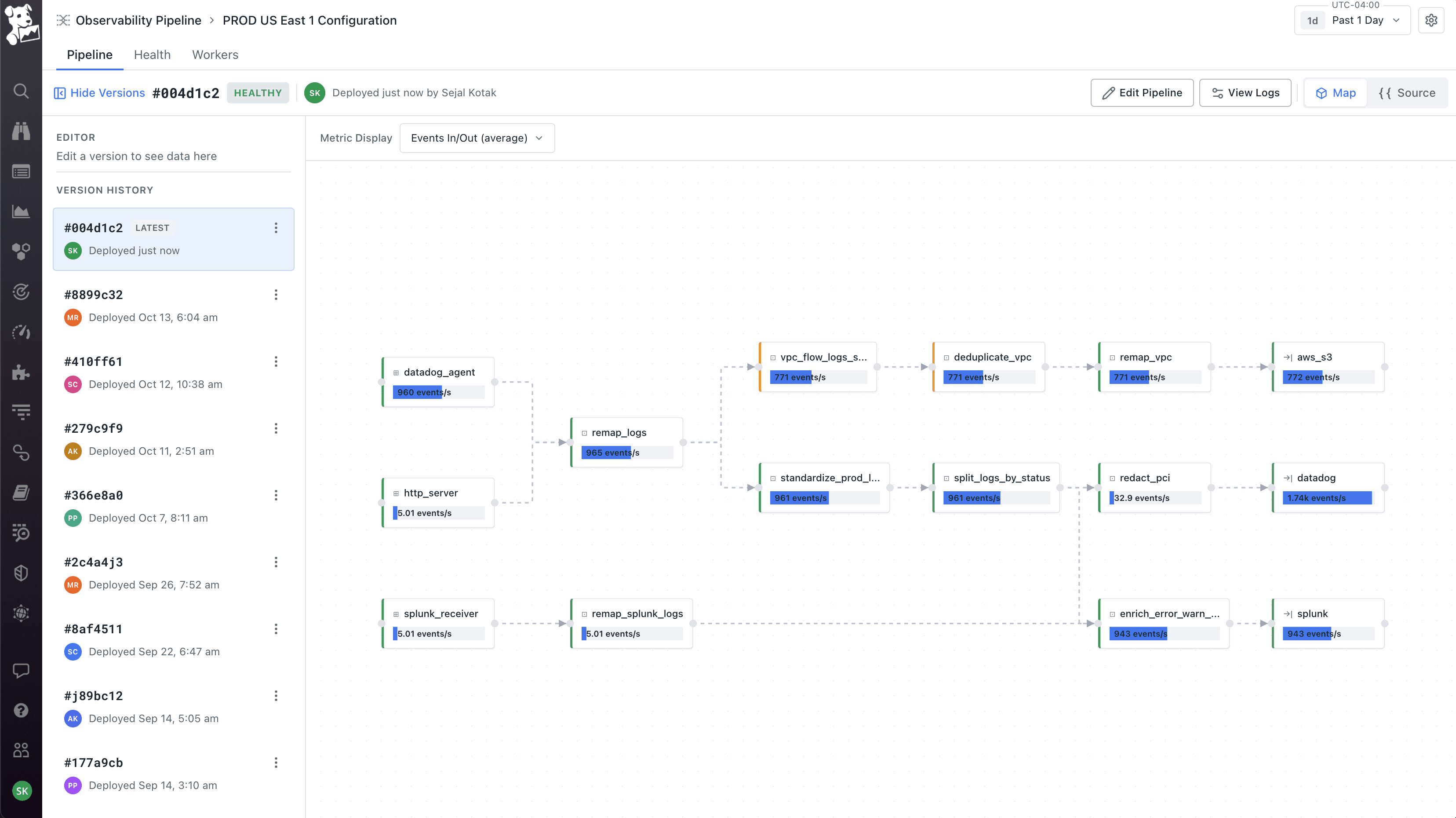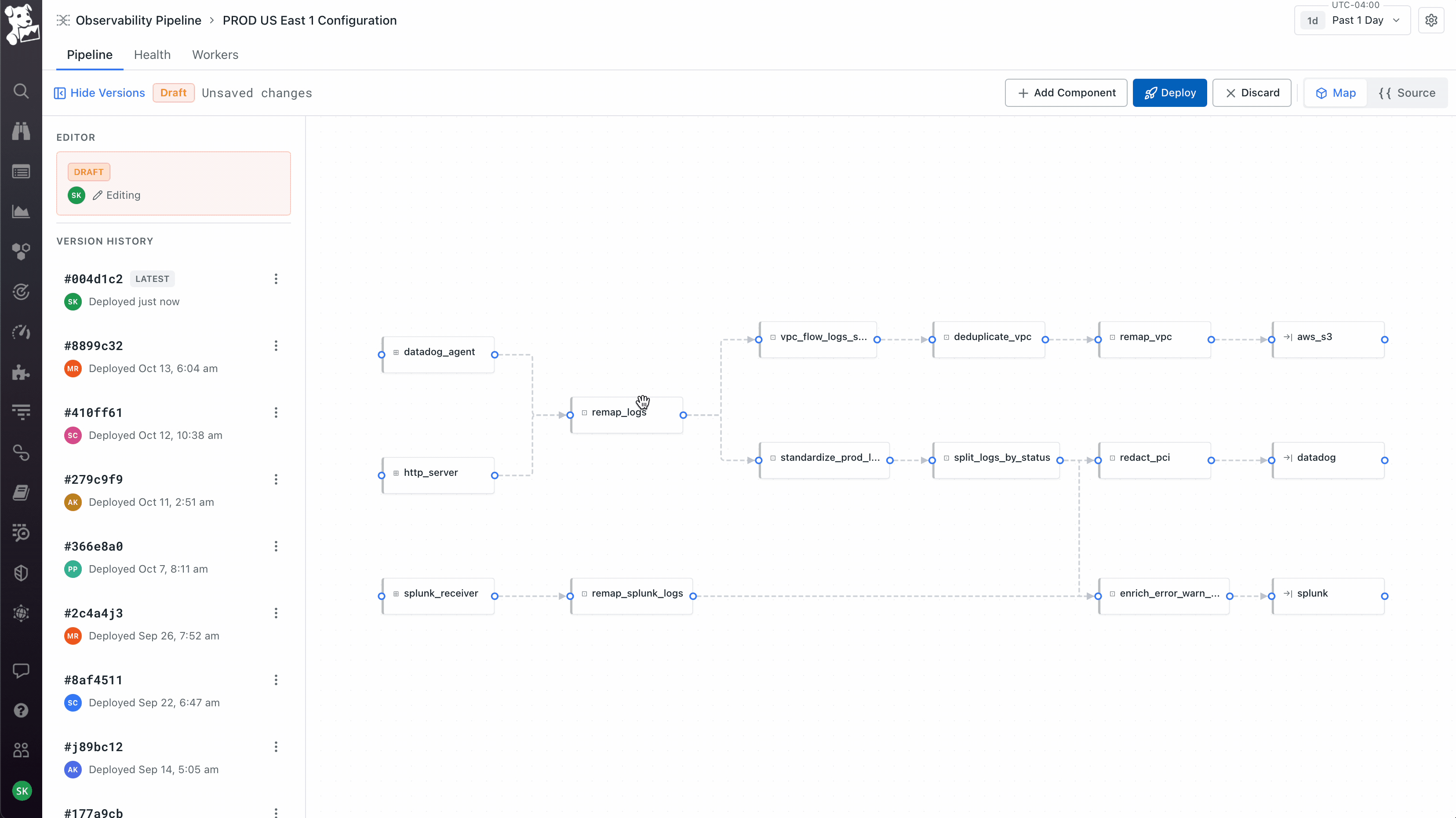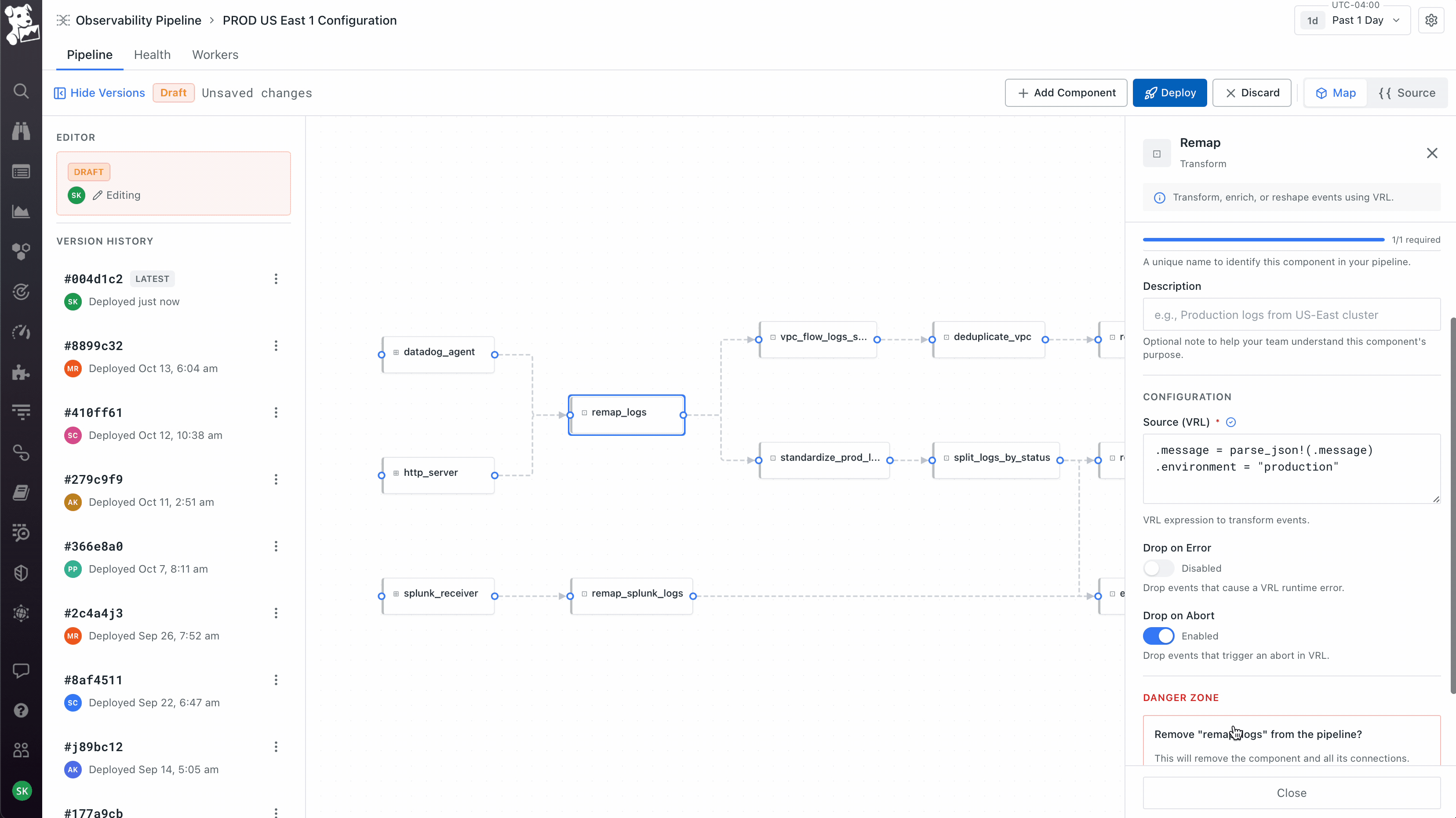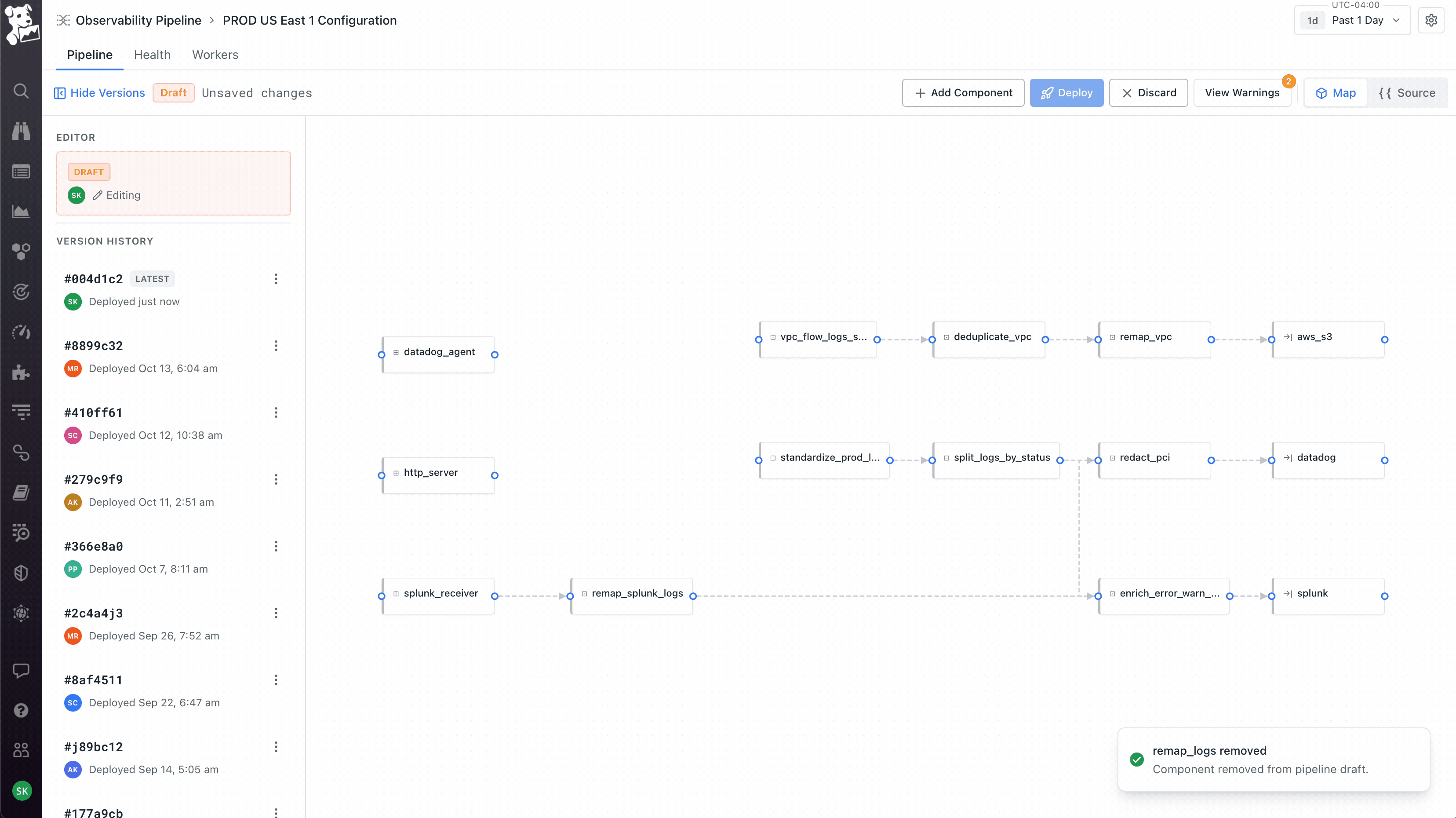
Visual canvas as the default, but with the underlying config as a peer view, not a hidden one. The canvas is the primary way to author – sources on the left, transforms in the middle, destinations on the right, live events-per-second on every node so you can see if data is actually flowing. But about half our users were code-first and would have rejected a tool that hid the config from them. So I made the Source view a first-class toggle alongside the canvas, always in sync – edit either one, the other updates. This was partly diplomatic with the Vector OSS community, who think of the config as the real artifact. It kept power users inside the product instead of pushing them back to the OSS workflow.
Visual canvas as the default, but with the underlying config as a peer view, not a hidden one. The canvas is the primary way to author – sources on the left, transforms in the middle, destinations on the right, live events-per-second on every node so you can see if data is actually flowing. But about half our users were code-first and would have rejected a tool that hid the config from them. So I made the Source view a first-class toggle alongside the canvas, always in sync – edit either one, the other updates. This was partly diplomatic with the Vector OSS community, who think of the config as the real artifact. It kept power users inside the product instead of pushing them back to the OSS workflow.
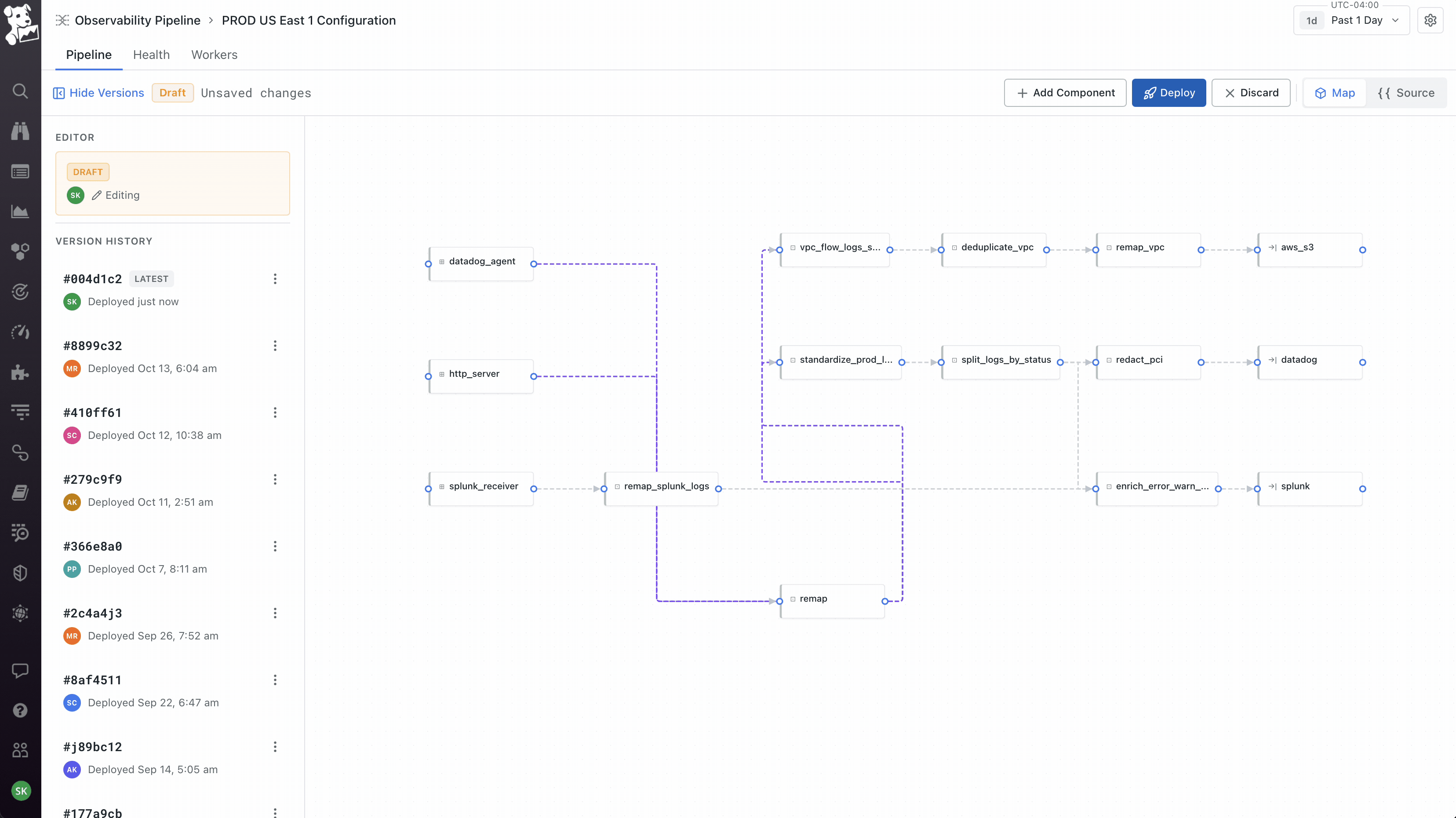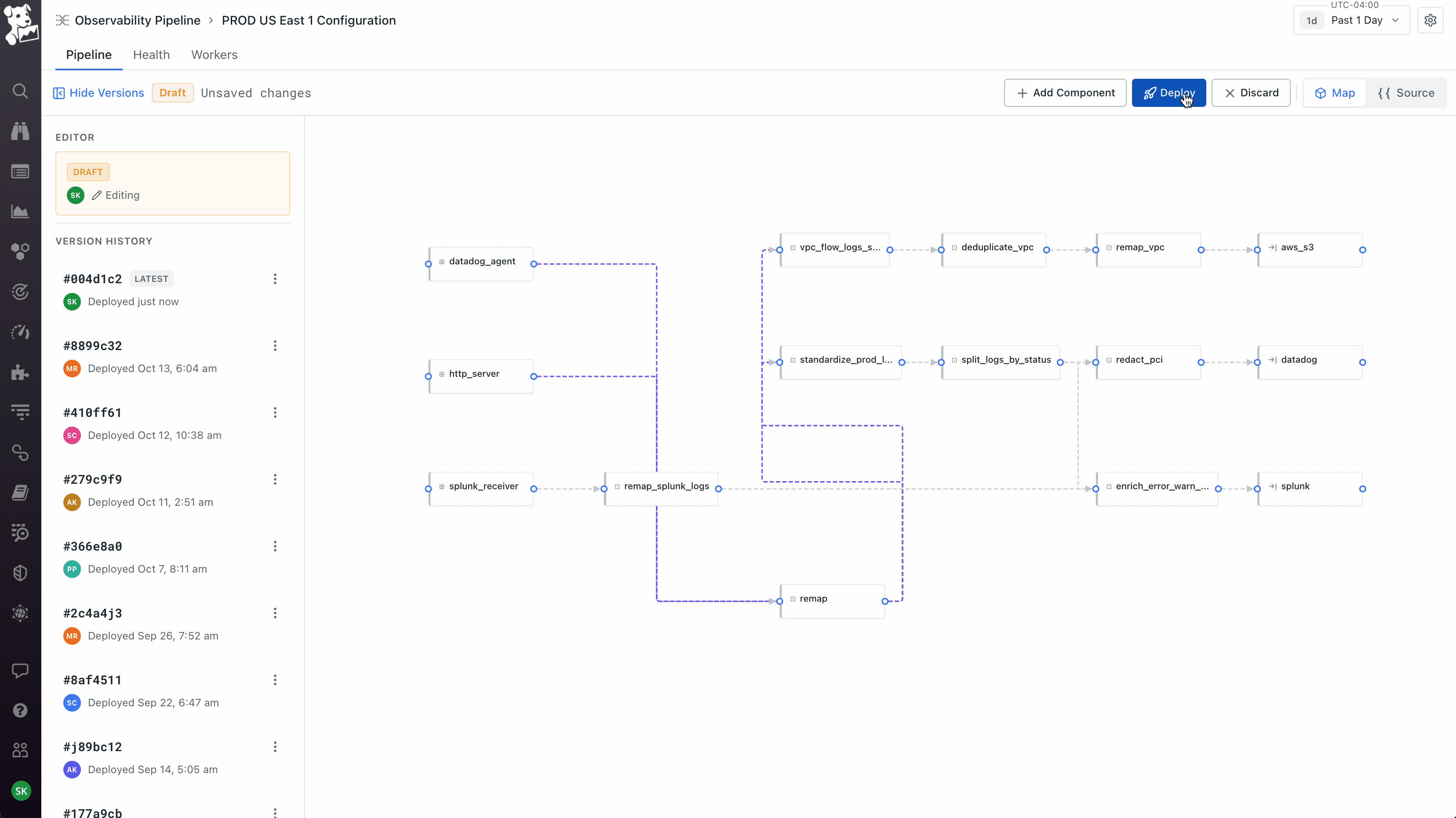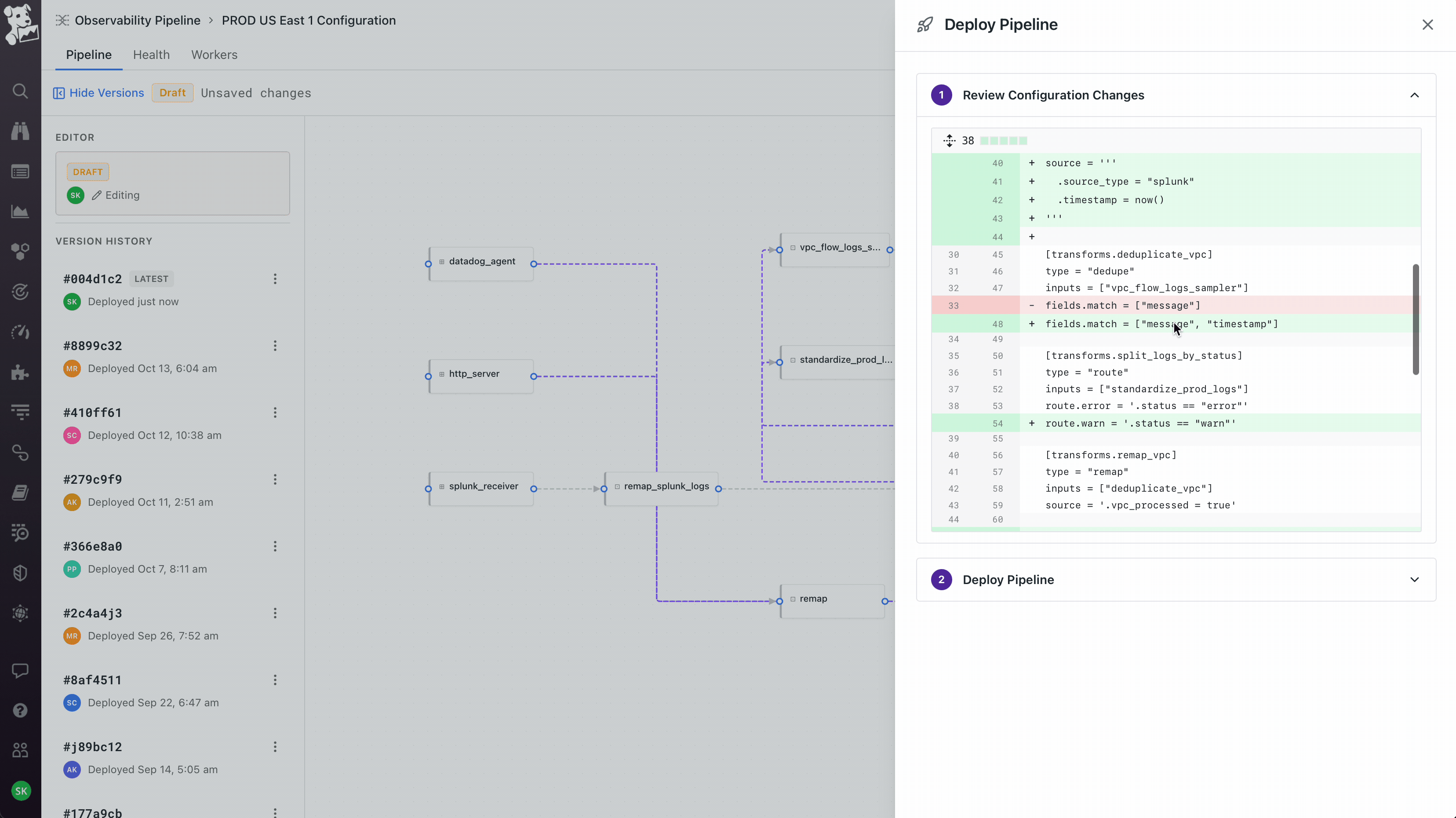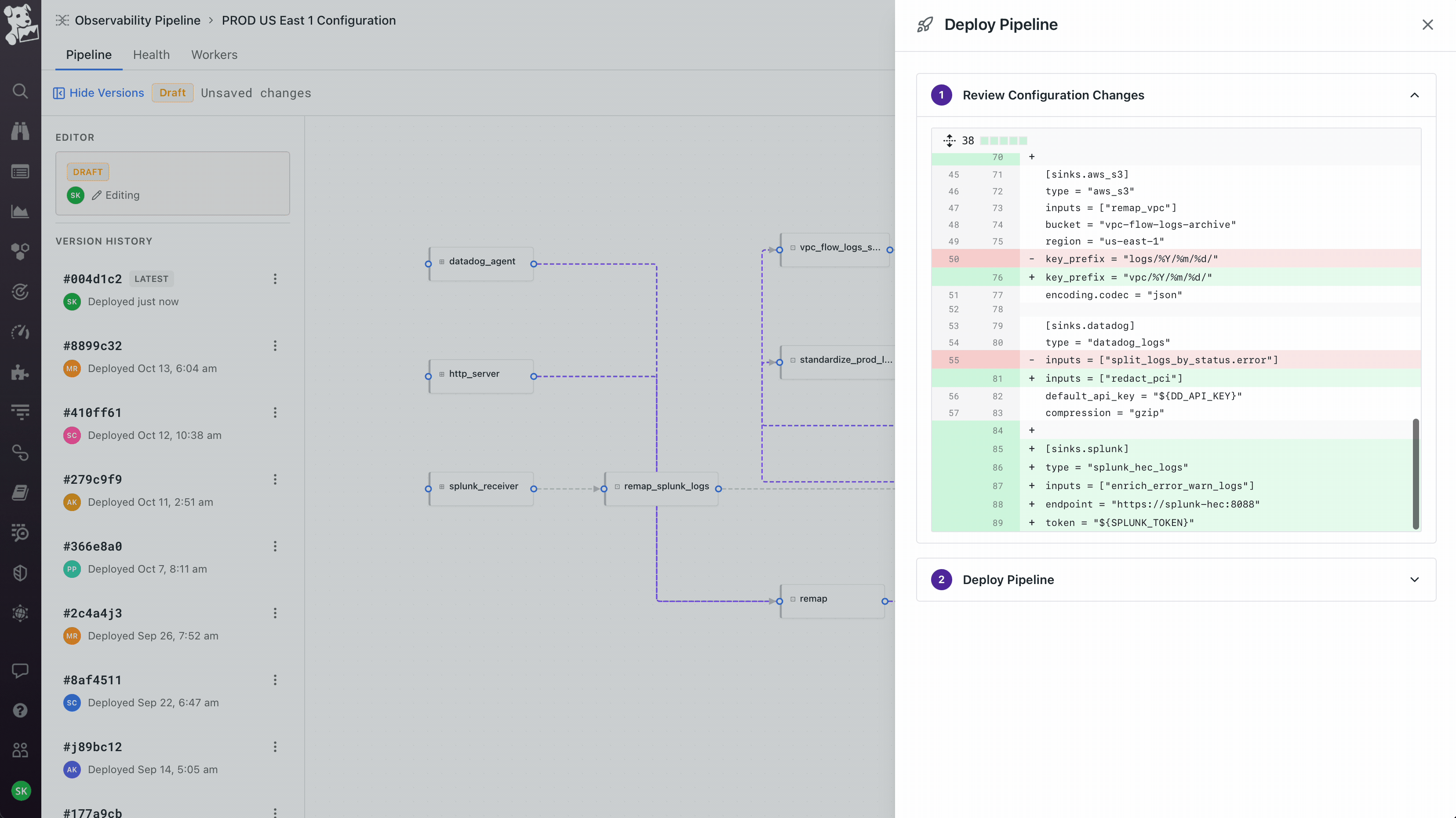
Treating deploy as the moment to earn trust, not abstract it away. When you click Deploy, you see a git-style diff of the underlying config – exactly what changed, line by line, before anything ships. After deploy, the Health view plots the current version against the previous one on the same chart, so you immediately see whether throughput improved or error rates moved. Versions are tagged, you can roll back, you can compare any two deploys. The visual canvas is meant to feel approachable; the deploy flow is intentionally engineering-flavored, because the people running production telemetry pipelines live in version control and would not have trusted a builder that felt like a black box.
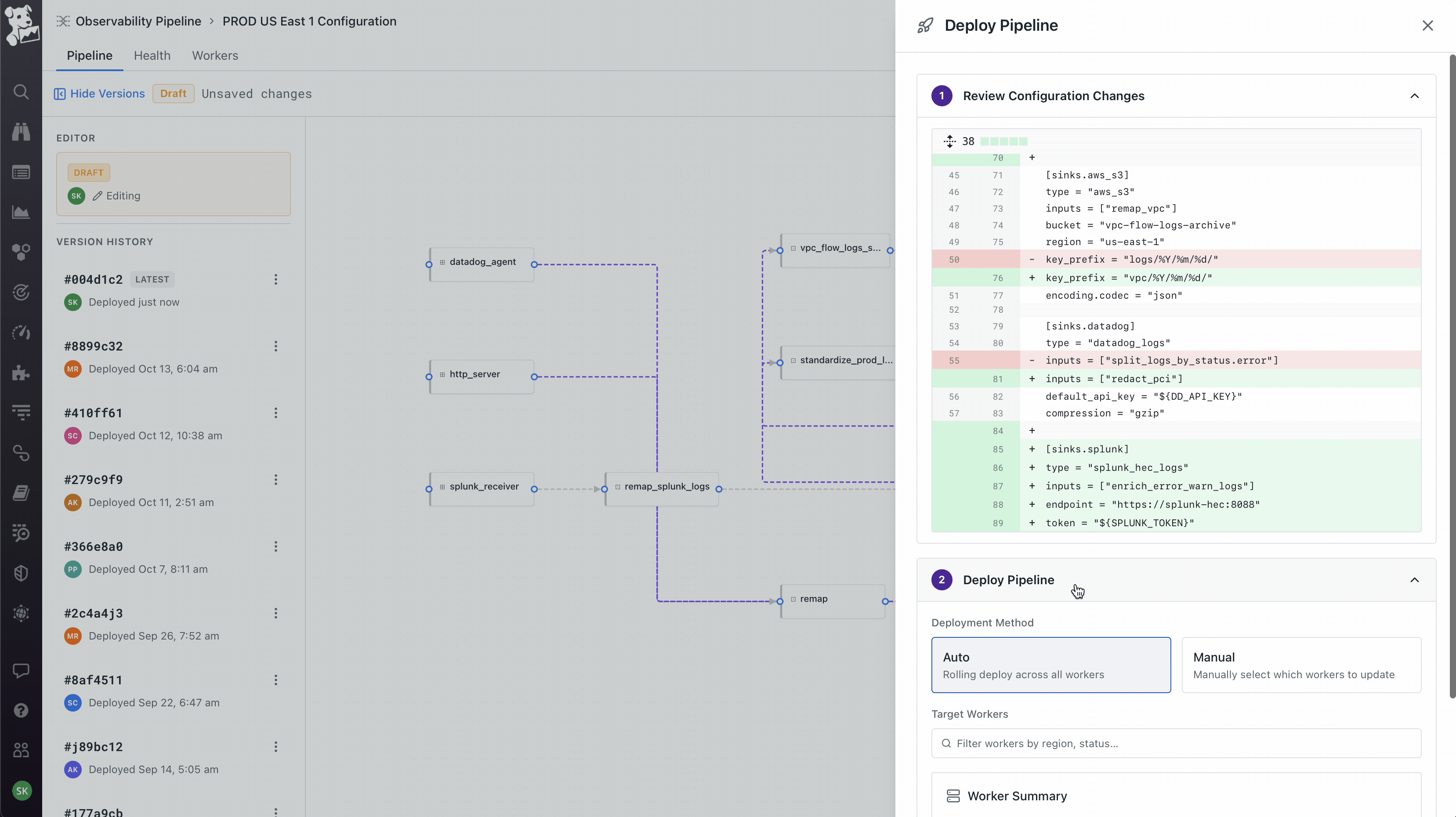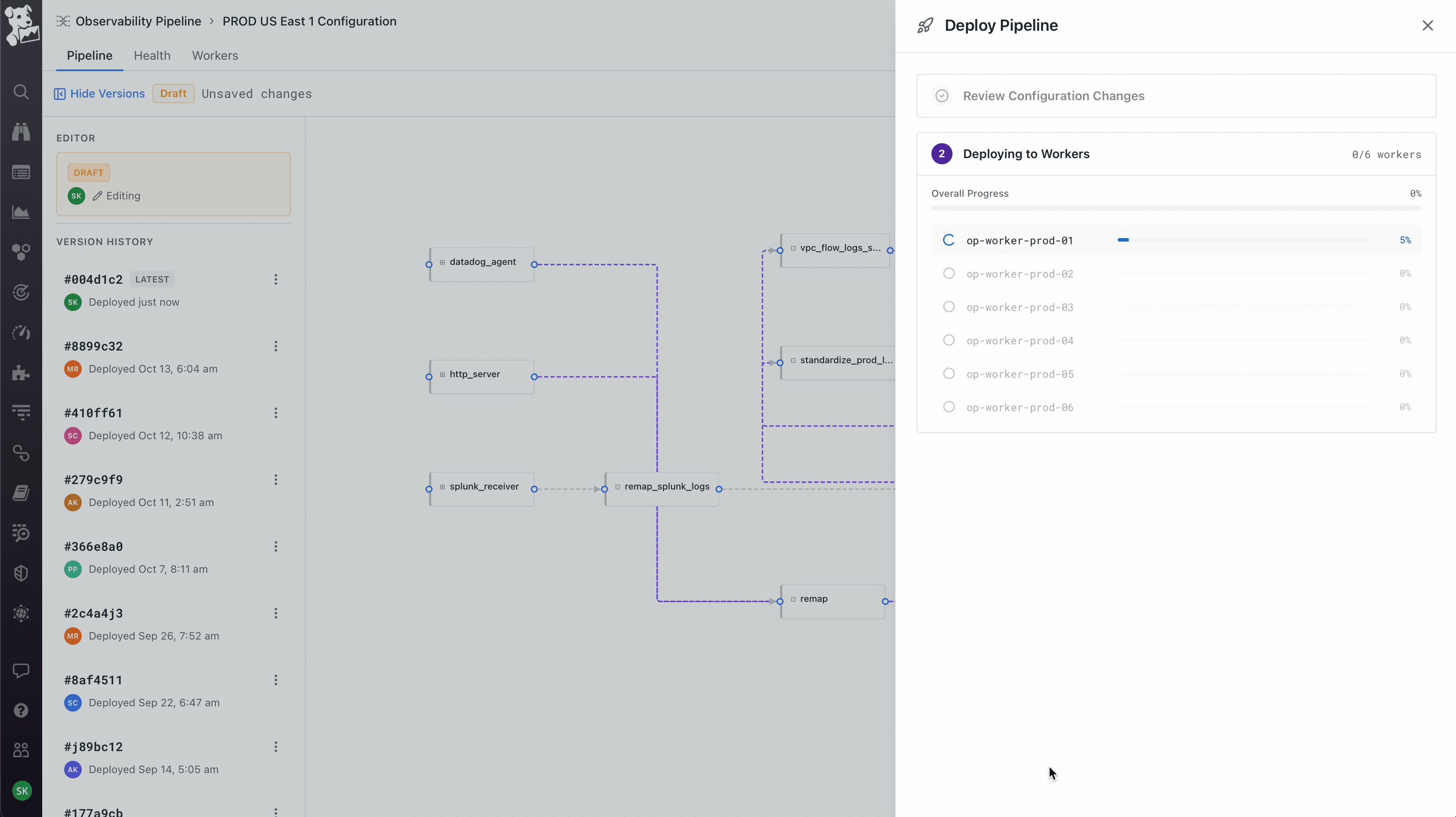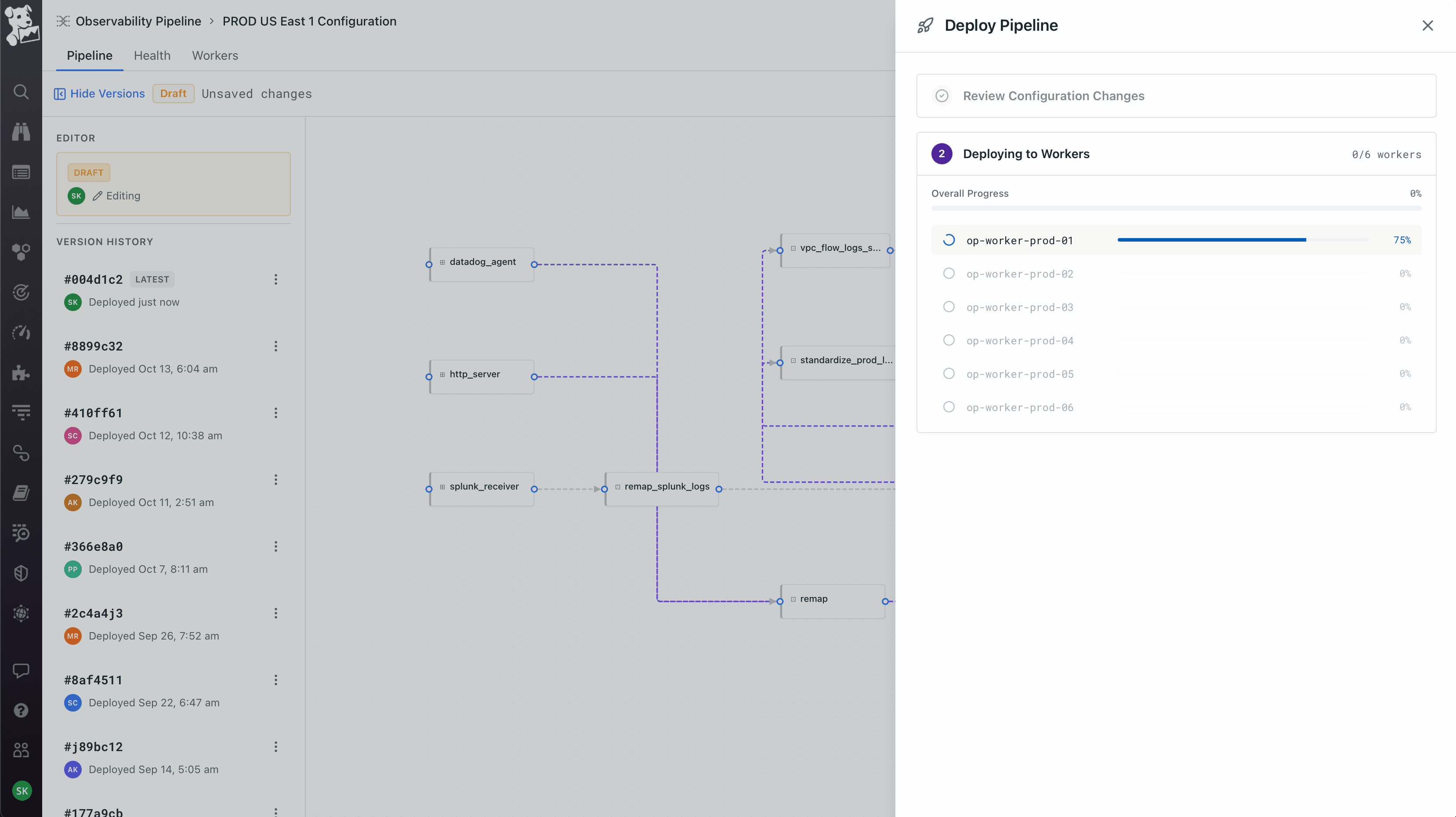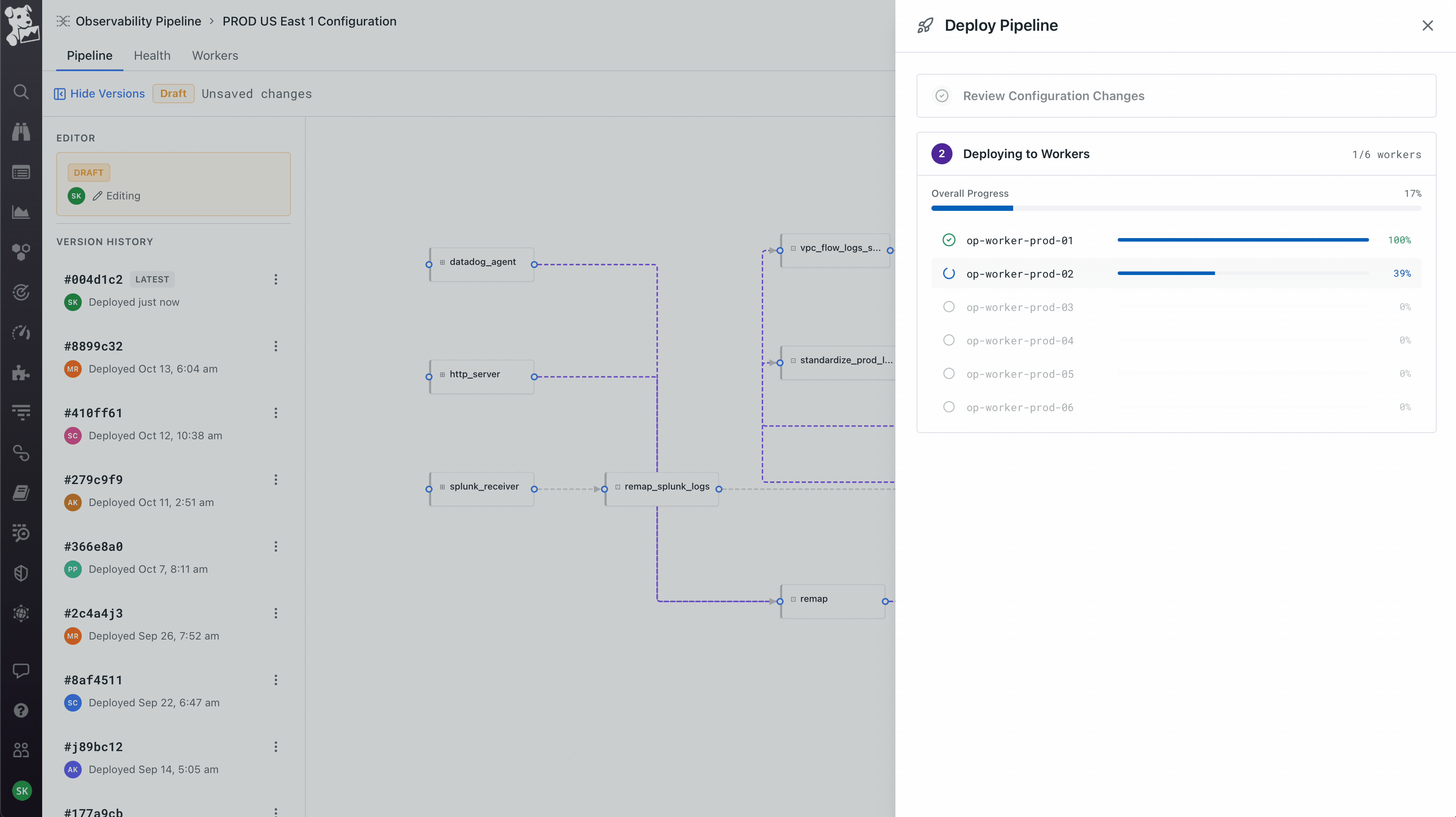
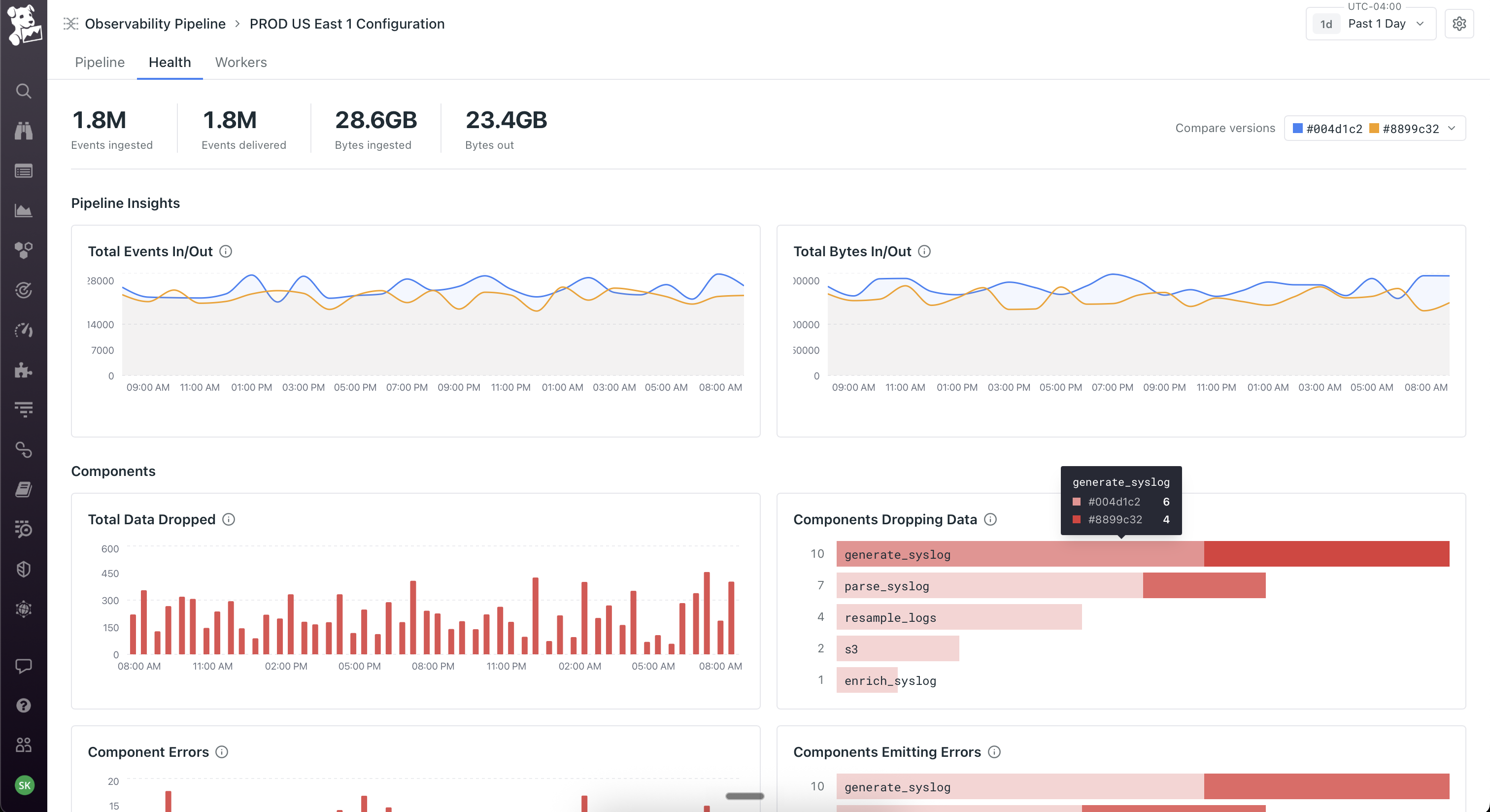
Workers as a first-class object, not an abstraction. The product team initially wanted to hide workers – click deploy, it just works. I pushed back because workers run on the customer's own infrastructure, which means the moment something goes wrong (and it always does eventually), an abstracted-away worker becomes a debugging nightmare. So workers got their own tab on every pipeline showing host, region, status, and per-worker metrics. Deploys are rolling with per-worker progress. This created the three-surface model the product still uses: Pipeline for what it's doing, Health for how it's performing, Workers for where it's running. You can pivot from a worker that's dropping data, to the node on the canvas where the loss is happening, to the version diff that introduced it. That cross-surface coherence took the longest to get right and is the part I'm most proud of.
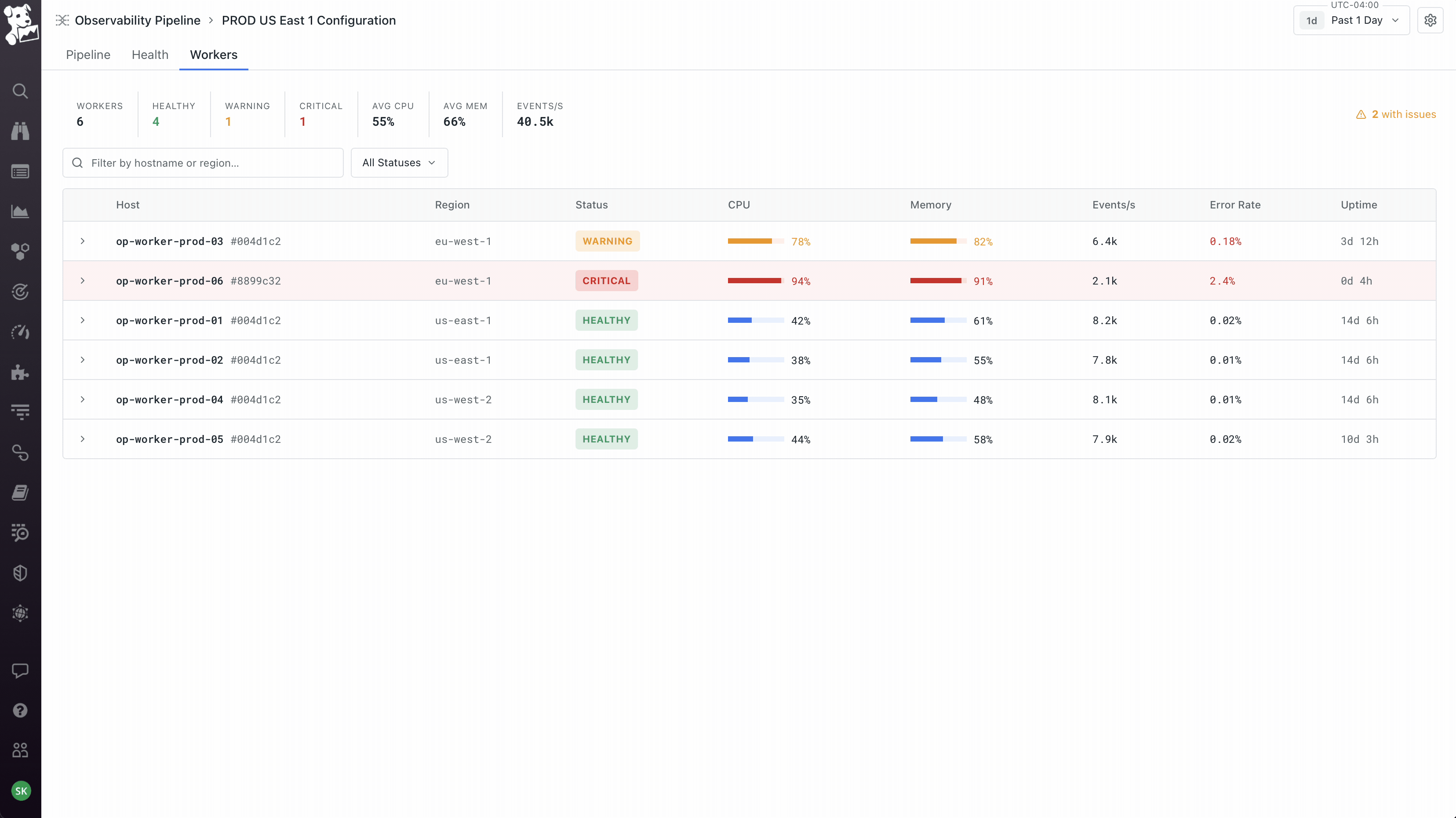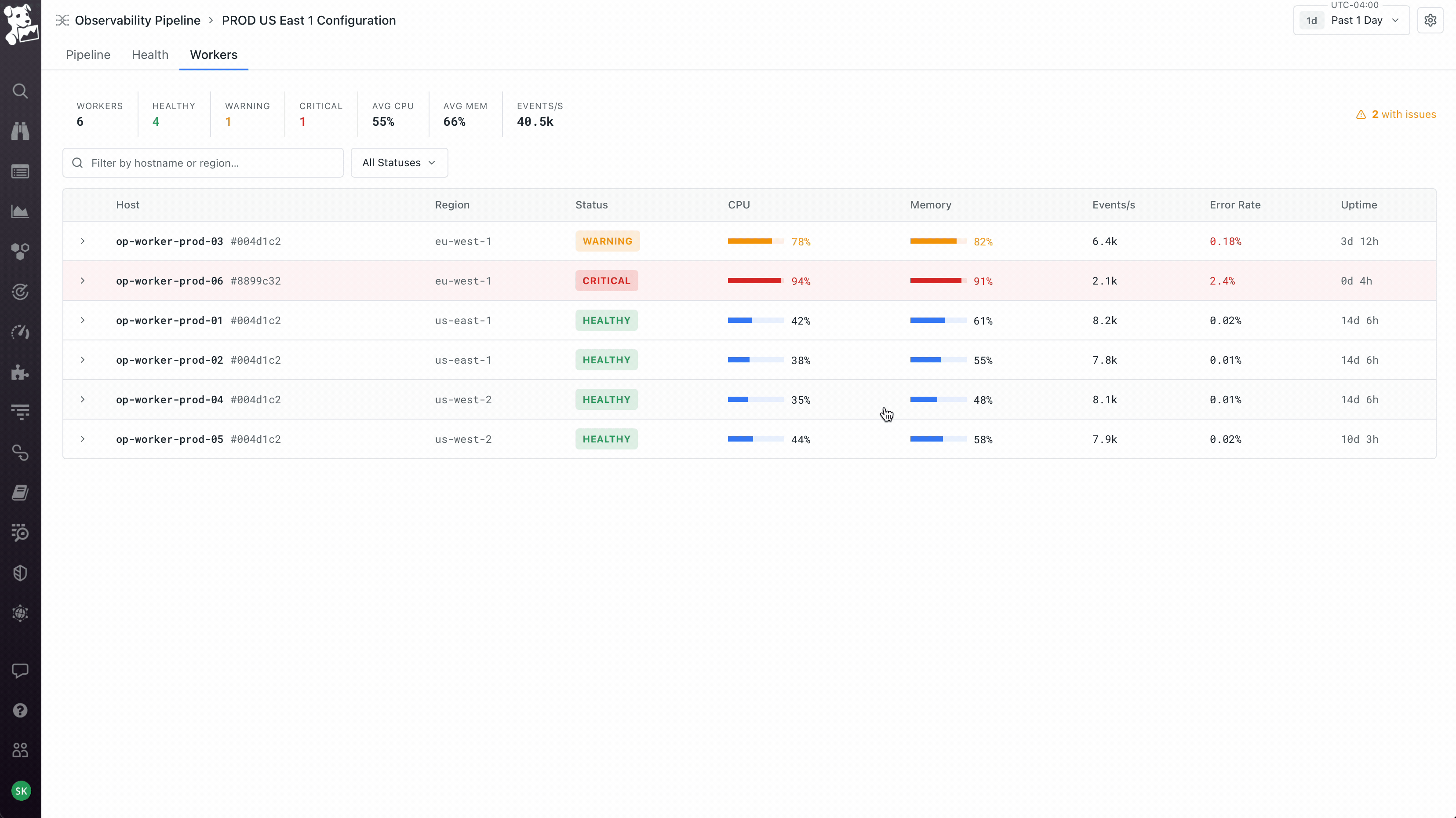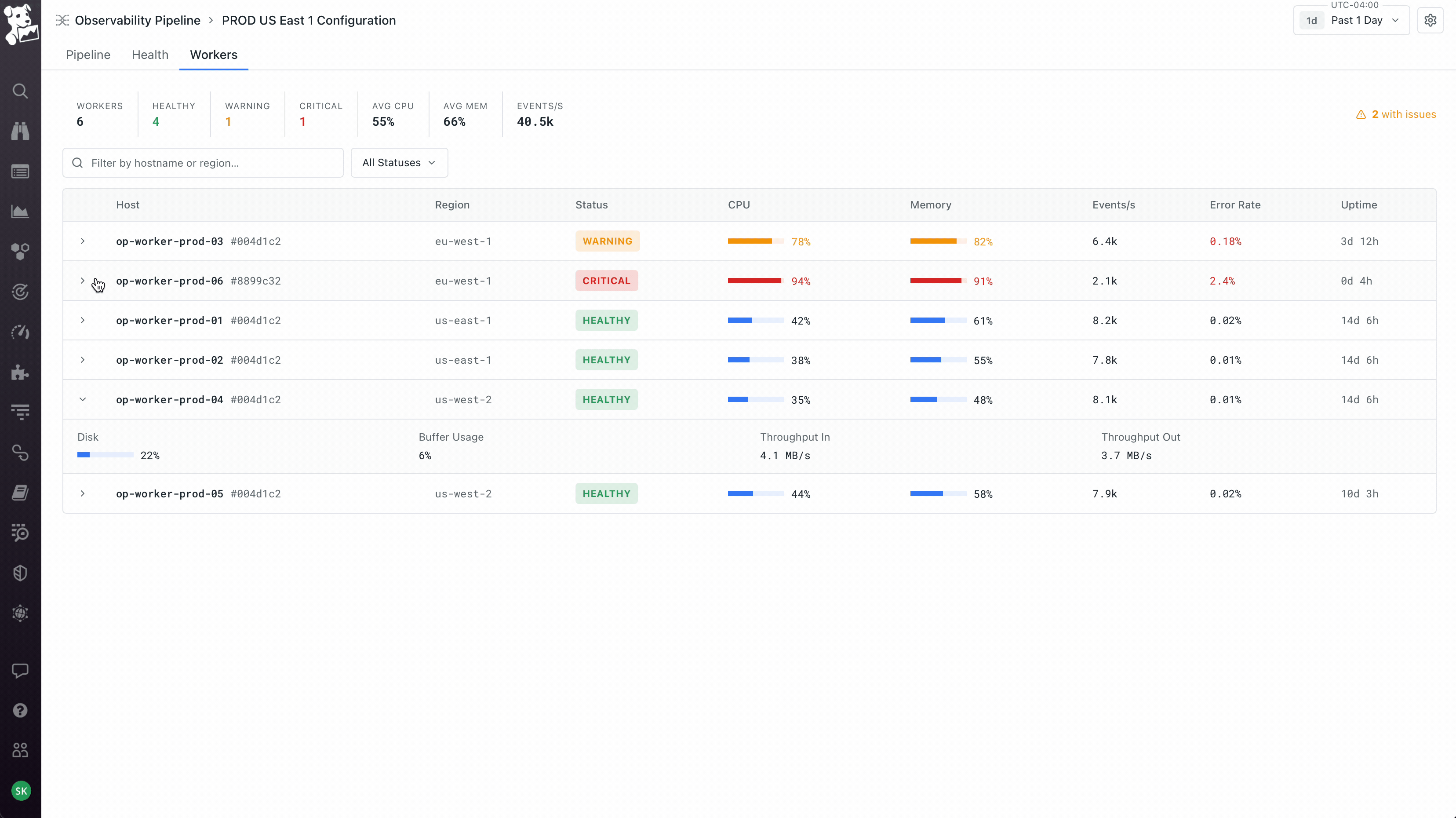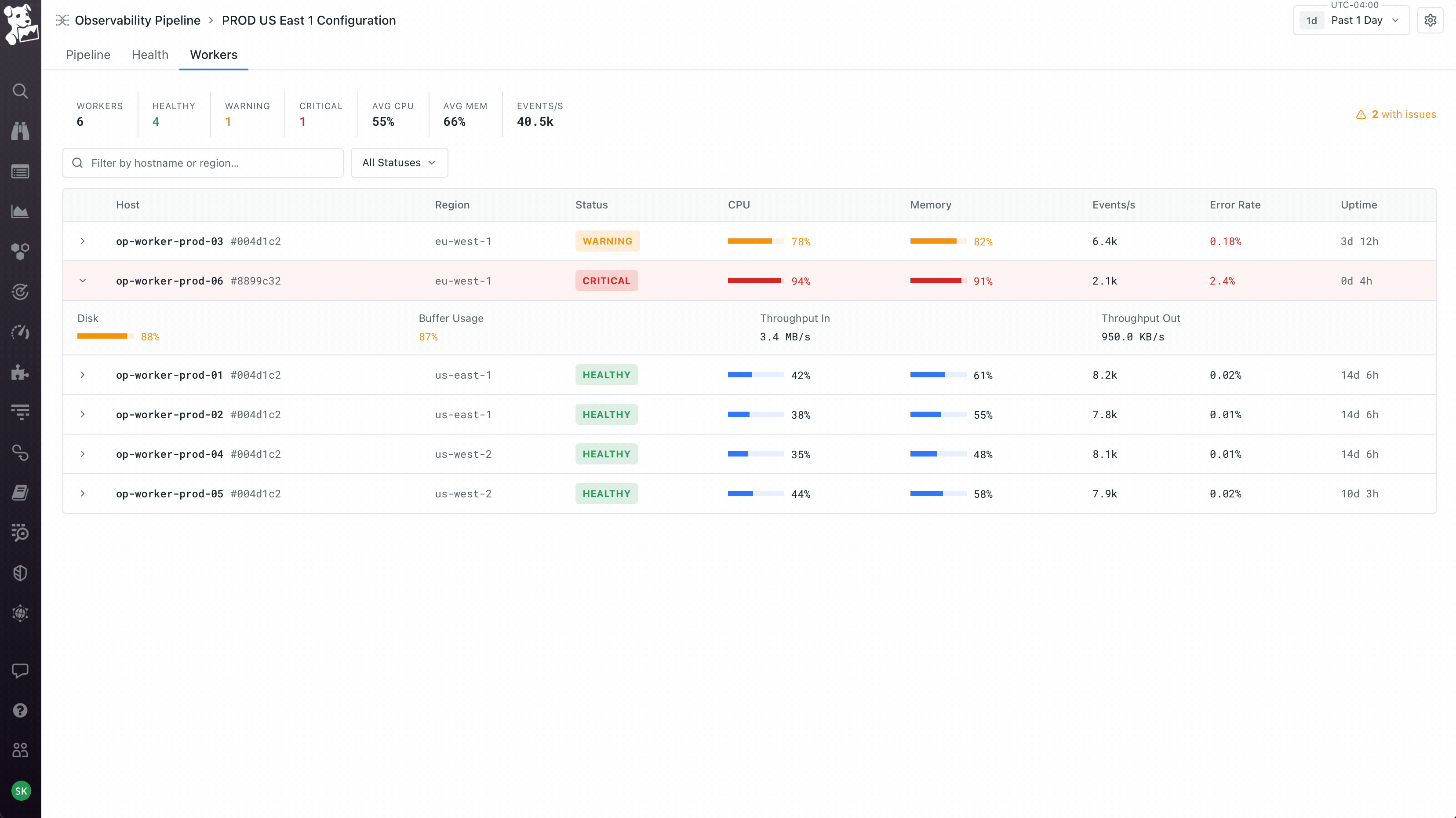
Launched June 2022. The product became Datadog's foundation for cost optimization and SIEM migration, and four years later the canvas, the deploy flow, and the workers tab are still the underlying structure – everything added since (AI-assisted Grok parsing, OCSF conversion, Cloudprem) sits on top of it.
If I were starting on this today I'd push harder on the worker install – it was the single biggest source of user friction and I was too quick to treat it as an engineering problem rather than a design one. I'd also build AI-assisted authoring into V1, but as something that drafts pipelines onto the canvas for the user to verify and edit, not as a chat replacement for the canvas itself. The interesting design problem isn't generating the pipeline – it's the handoff between the AI's suggestion and the user's verification, which is fundamentally a trust problem.